

![图片[1]-DDSP-SVC开源声音模型训练工具-创梦星际](https://fileass.ddwoo.top:10006/i/2025/01/17/ib90k7.png)
DDSP-SVC6.1简介
DDSP-SVC6.1是一个基于DDSP(Differentiable Digital Signal Processing)技术的实时端到端歌唱声音转换系统。它旨在为个人电脑用户提供一个性能卓越、易于使用的AI变声解决方案。该系统以其快速的收敛速度和较低的资源消耗而受到用户的青睐,同时在音色转换上表现出色,提供了更为自然和丰富的音质体验。
主要特点:
- 性能提升:相较于前一版本,DDSP-SVC6.1在音色转换上更加精准,减少了音色遗漏,同时在音域上有所扩展。
- 硬件兼容性:该系统对硬件的要求不高,仅需4G及以上的NVIDIA显卡,通过启用半精度(FP16)进一步降低了内存占用。
- 开源项目:DDSP-SVC6.1是一个开源项目,用户可以在GitHub上找到其源代码和相关文档,方便进行个性化定制和优化。
- 实时变声:系统支持实时GUI操作,用户可以直接在界面上进行声音变换,无需复杂的设置。
- 持续优化:尽管DDSP-SVC6.1已经表现出色,但项目团队仍在不断试验和优化网络参数,以期达到更高的性能。
版权声明: DDSP-SVC6.1项目由yxlllc开发和维护。所有代码和文档均受版权保护,未经作者明确授权,不得用于商业用途。用户可以自由下载、修改和分发该软件,但必须遵守相应的开源许可证规定。
作者信息:
- 主要开发者:yxlllc
- GitHub项目地址:DDSP-SVC GitHub
SVC-Fusion是由B站UP主多玩幻灵qwq制作
1:下载和部署
点击链接加入群聊【幻灵的炼丹工坊】:
获取整合包链接后进入网盘下载(目前 Fusion 使用 123 网盘发布)
下载完成后用 bandizip 或 7-zip 进行解压(不要使用 winrar,会出现解压文件损坏的报错)
7-Zip官网:7-Zip
解压完成后进入整合包(整合包本体如下)
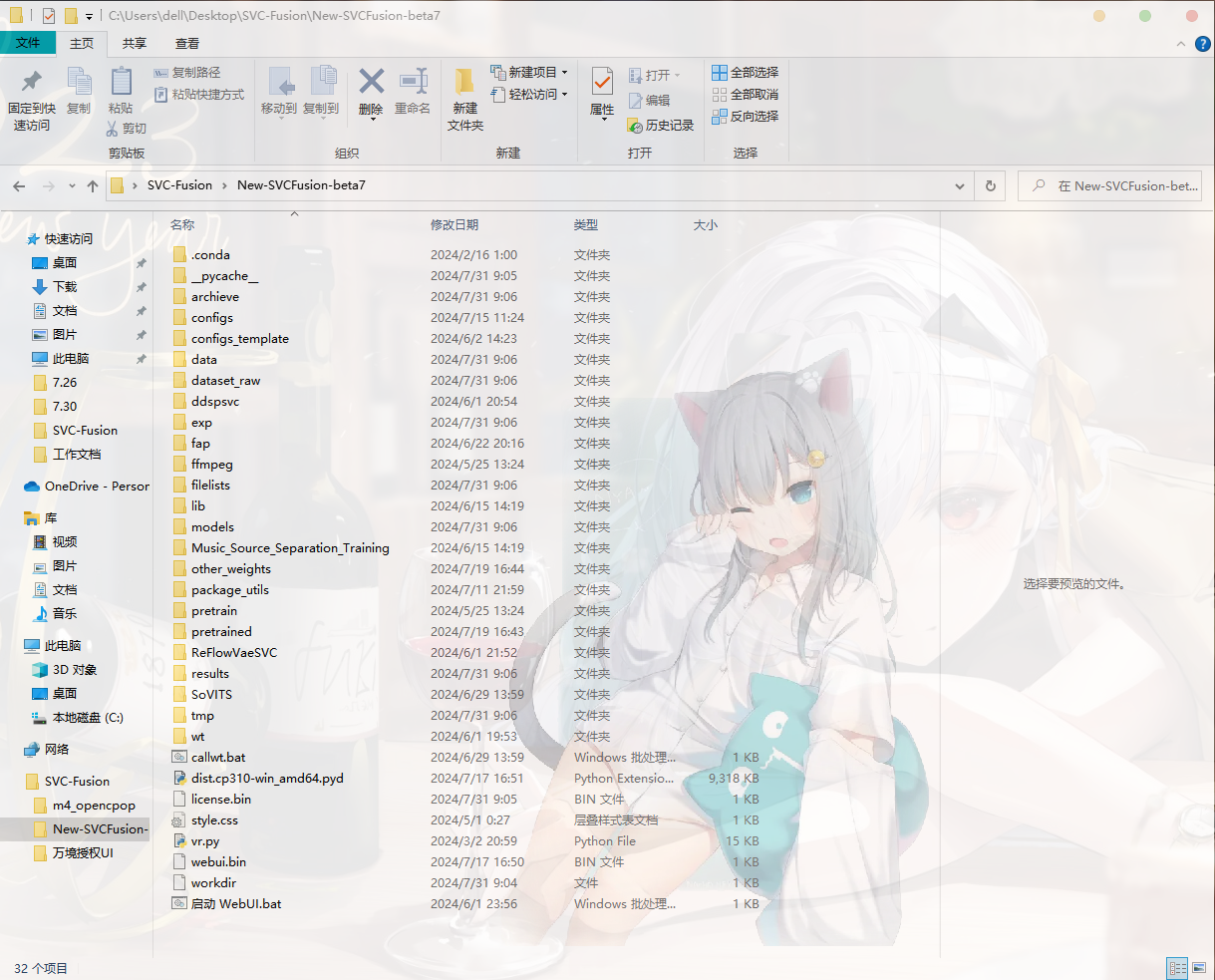
文件结构说明
| 文件夹 | 说明 |
|---|---|
| exp | 工作目录 |
| archieve | 训练归档文件夹 |
| models | 已训练模型文件夹 |
| dataset_raw | 原始数据集文件夹 |
| data | 可用于训练的数据集存放位置,完成训练后可删除 |
| tmp | 数据处理临时文件夹,完成数据处理后可删除 |
2:SVC-Fusion,启动!
双击启动 WebUI.bat

初次启动可能需要等待一段时间。
出现提示框后,点击我同意,进入网页。
此时 cmd 控制台大概是这样的(使用 Fusion 时请勿关闭控制台!)
浏览器将自动打开网页,如下
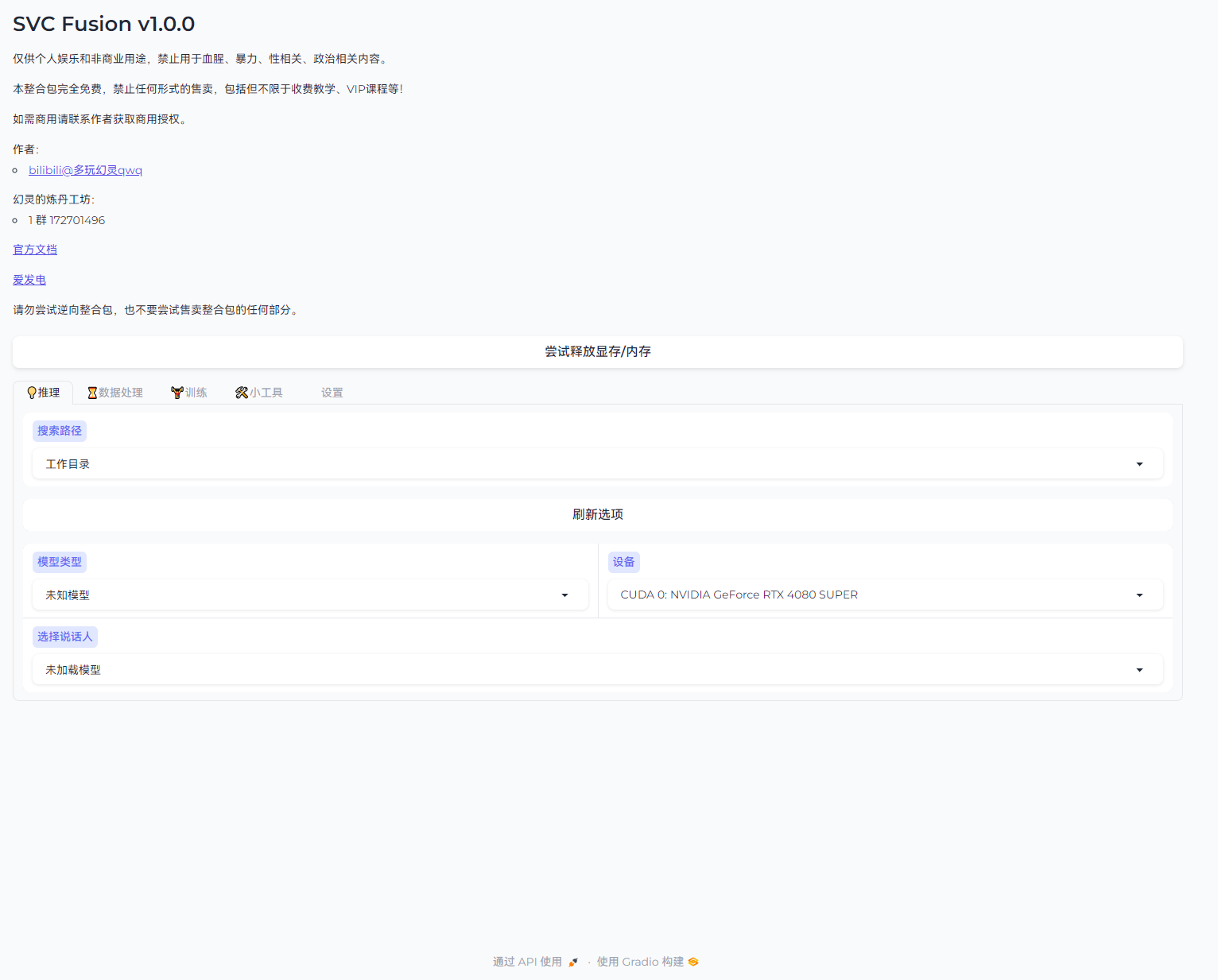
TIP
推荐使用 Edge、Chrome 浏览器打开网页,并关闭网页翻译和加速器。
打开 webui 的过程中可能会出现若干警告,具体请详见文末的常见报错。
3:预处理
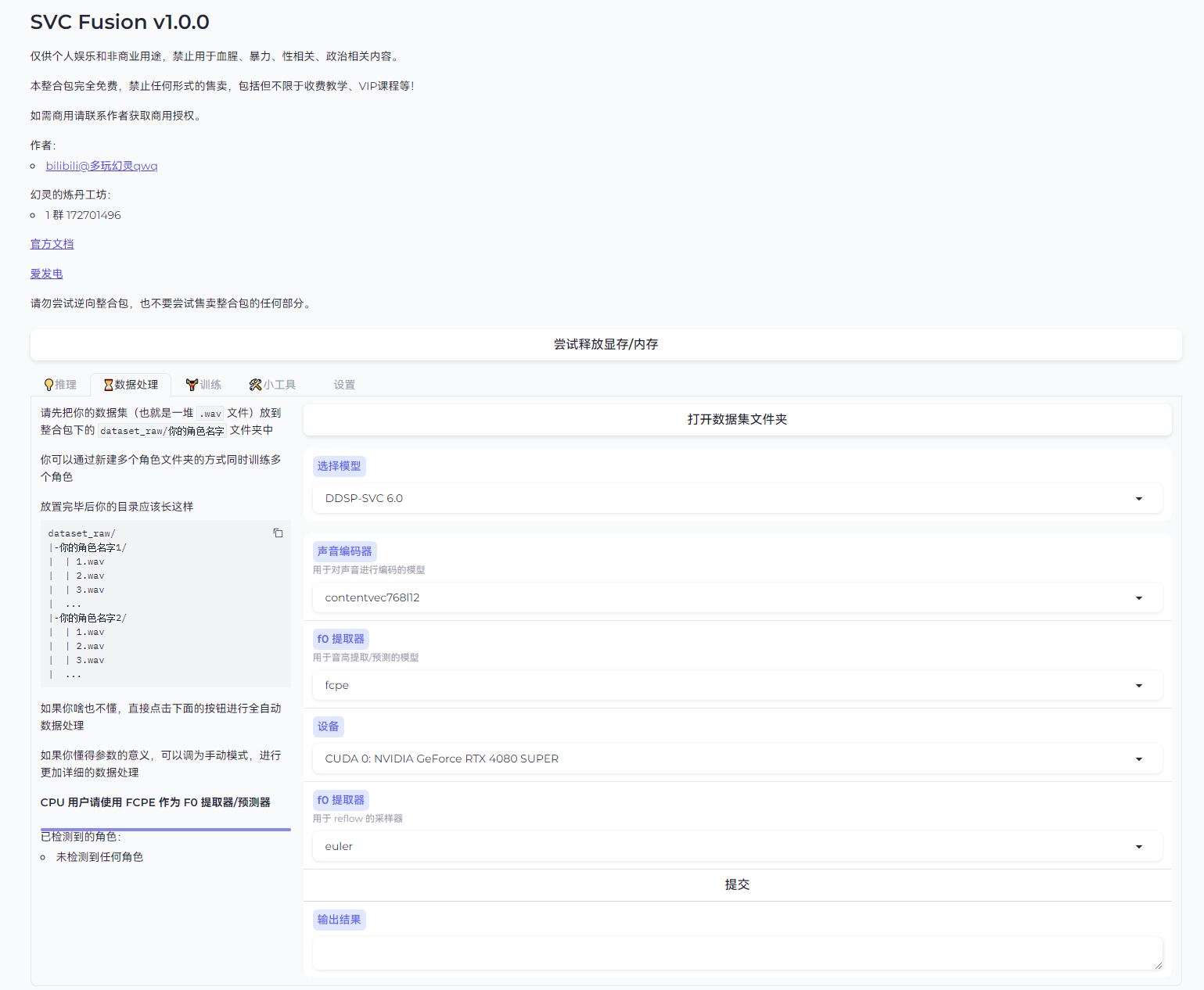
点击“打开数据集文件夹”进入 dataset_raw 文件夹
将准备好的数据集打包成文件夹放入此处,注意文件结构
dataset_raw/
|-你的角色名字 1/
| | 1.wav
| | 2.wav
| | 3.wav
| ...
|-你的角色名字 2/
| | 1.wav
| | 2.wav
| | 3.wav
| ...TIP
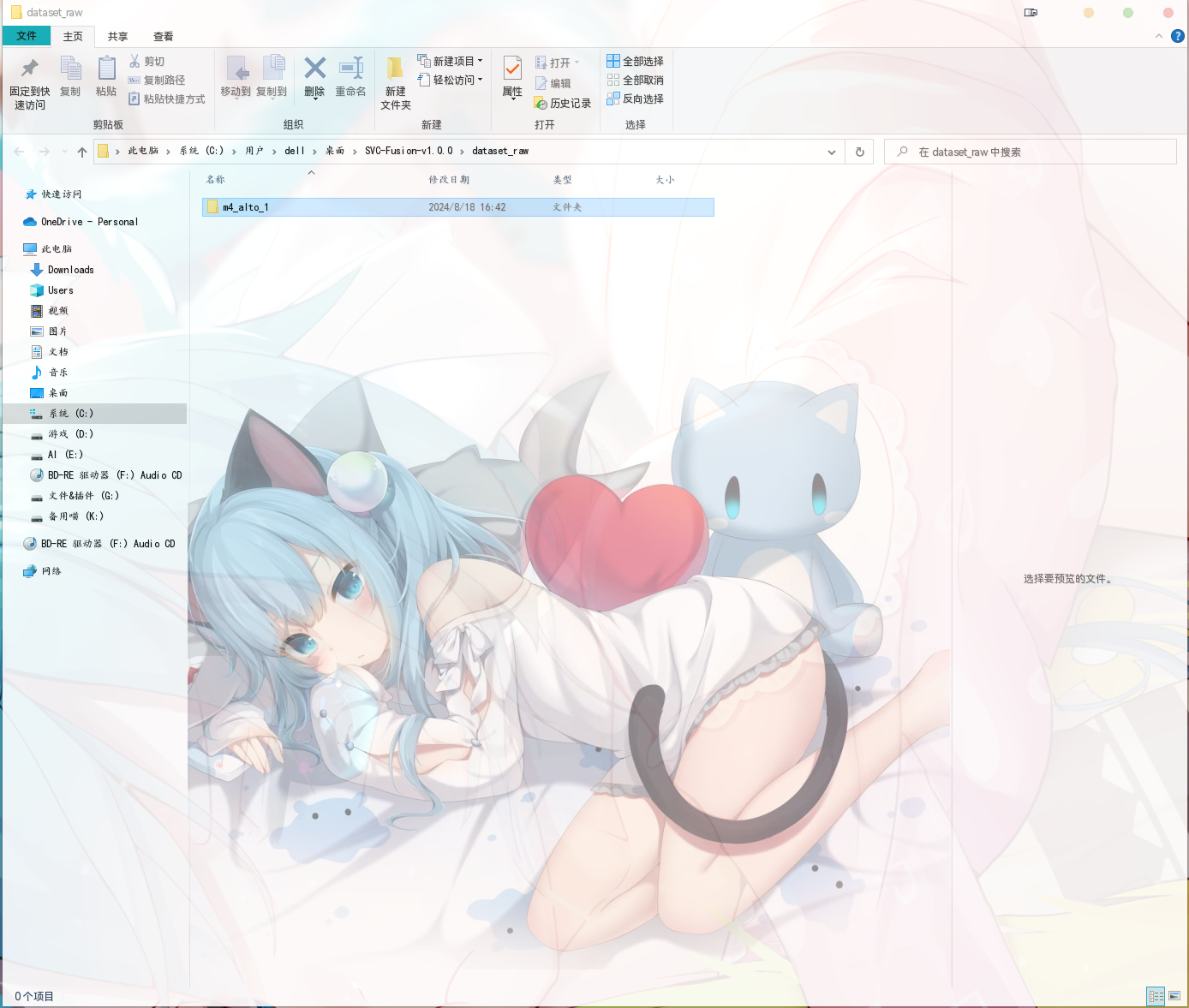
如果是单说话人,你的 dataset_raw 文件夹里面应该是这样的
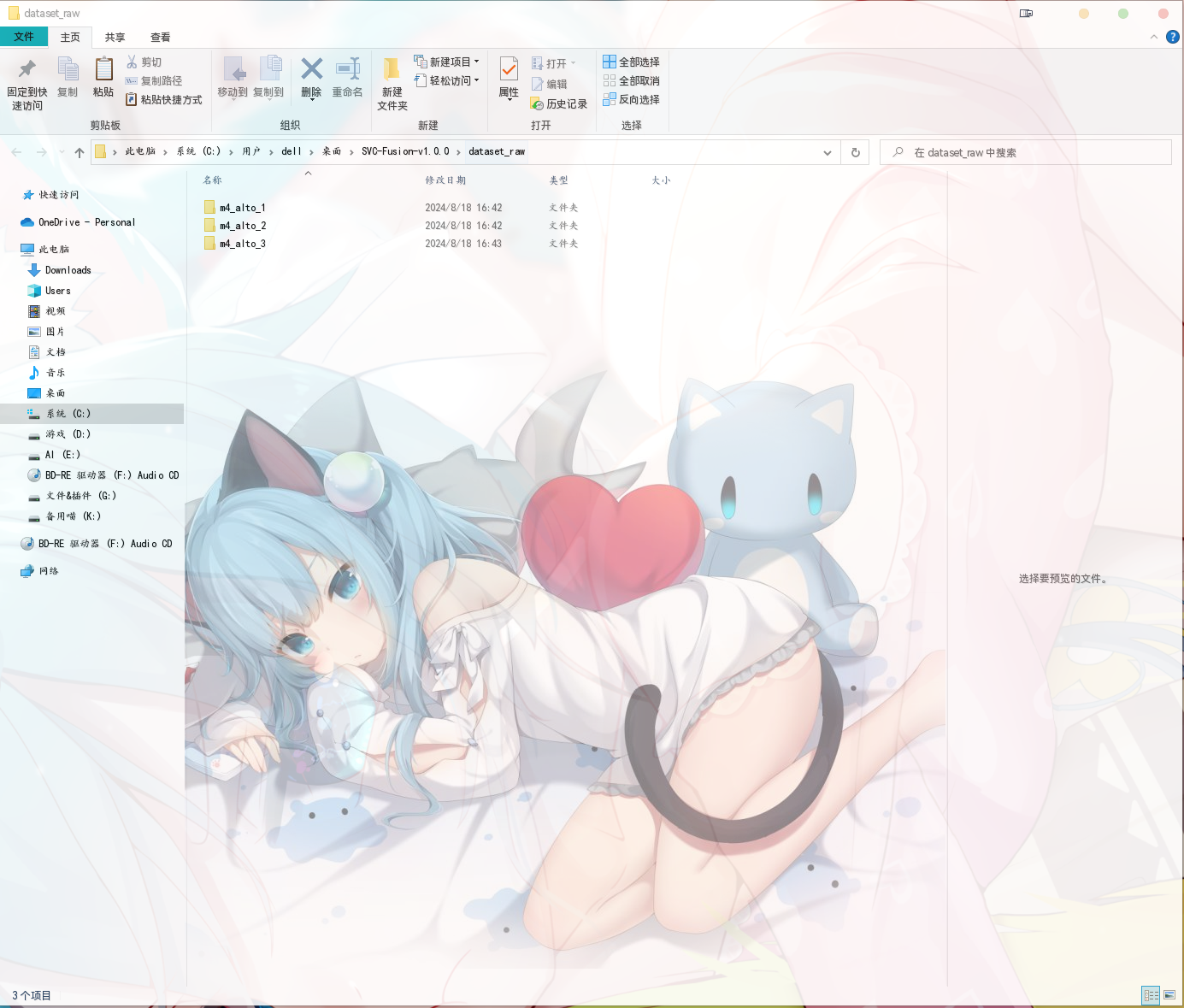
如果是多说话人,你的 dataset_raw 文件夹里面应该是这样的
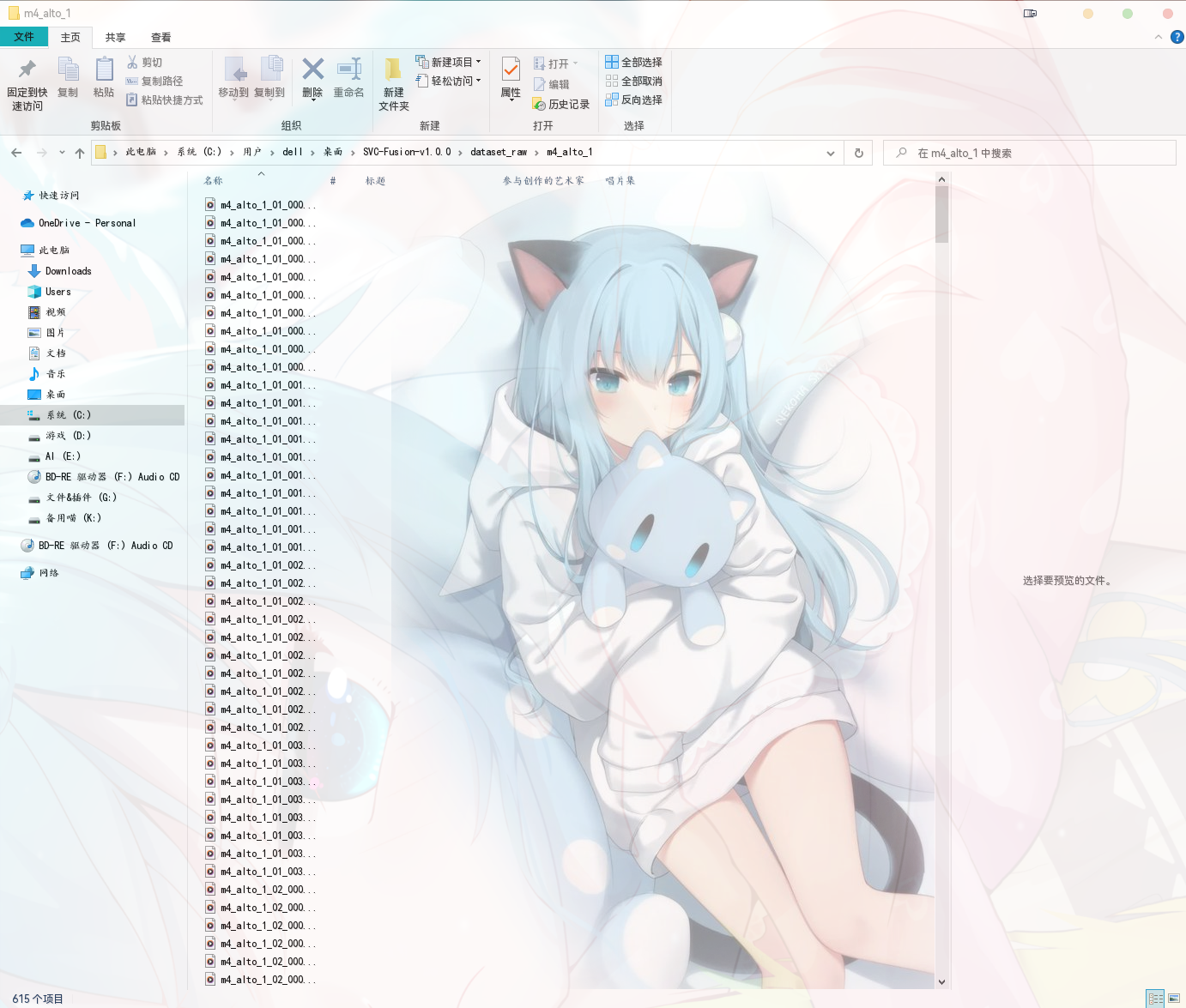
数据集文件夹里应当是这样的
注:数据集命名若包含 特殊字符或中文 则 可能 在处理时发生报错,可使用未鸟的批量重命名工具进行修正。
为了能够直观地教学,本次以单说话人进行示范。
回到网页,选择数据处理,进行预处理
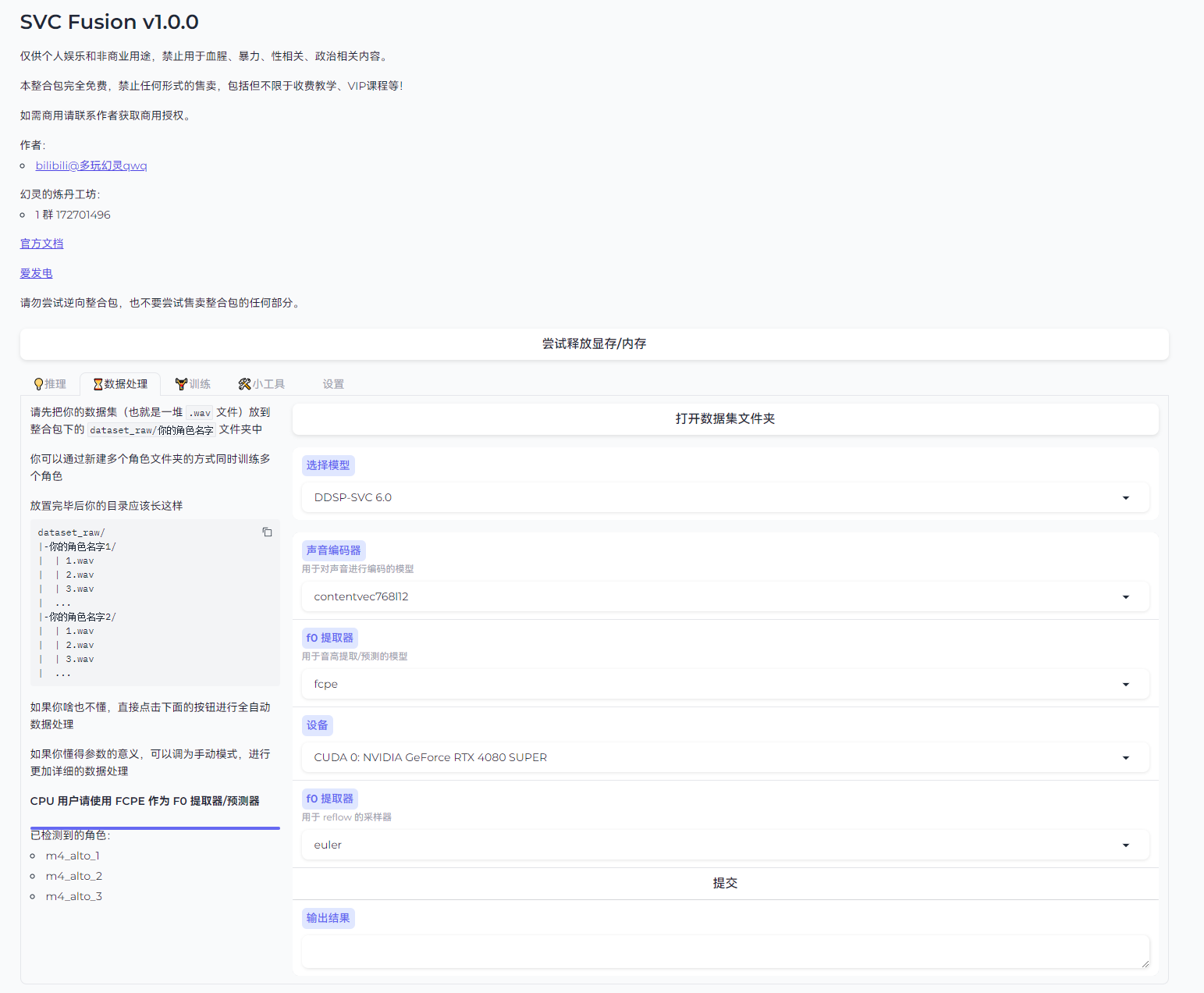
选择需要的算法(算法选择参考前文)`
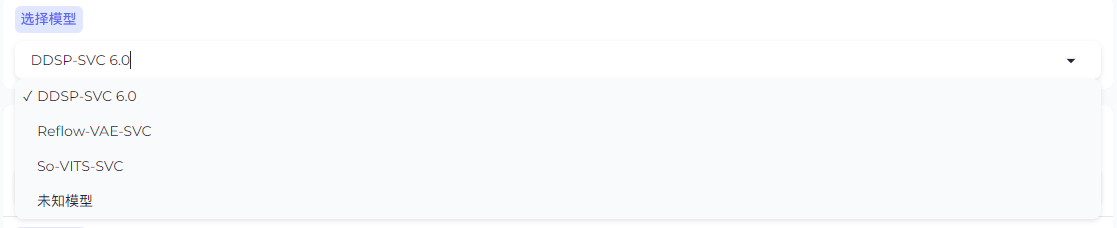
若选择 sovits,则另有几个选项,按需勾选(如果不懂不建议乱动)
选择声音编码器(目前仅支持 768)

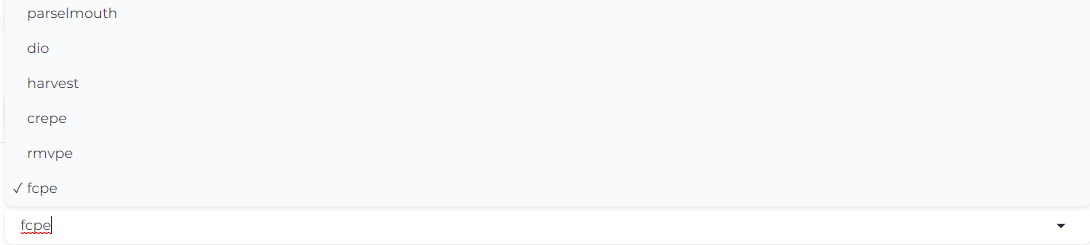
选择 F0 预处理器(通常为默认)

选择设备进行训练(DDSP 支持 cpu 计算)

此处以入门卡作演示

然后选择用于 reflow 的采样器

选择完成后,点击”提交“进行预处理

预处理完成
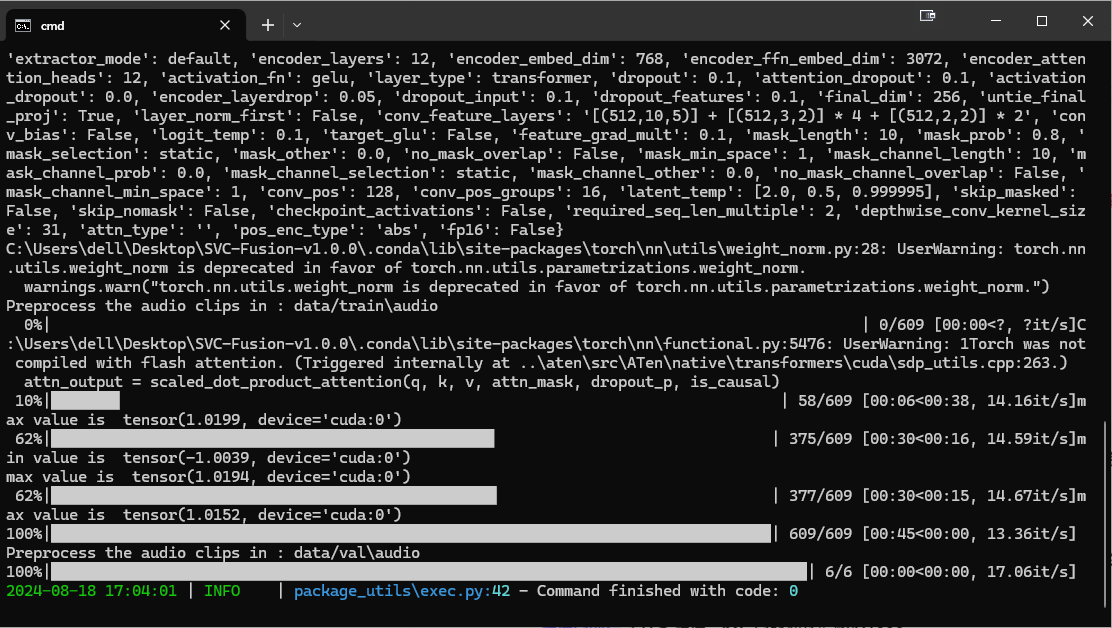

注:本教程以 ddsp6.0 为模型,其他算法的预处理/训练/推理界面略有不同,但操作逻辑相似。
4:训练
点击进入训练界面
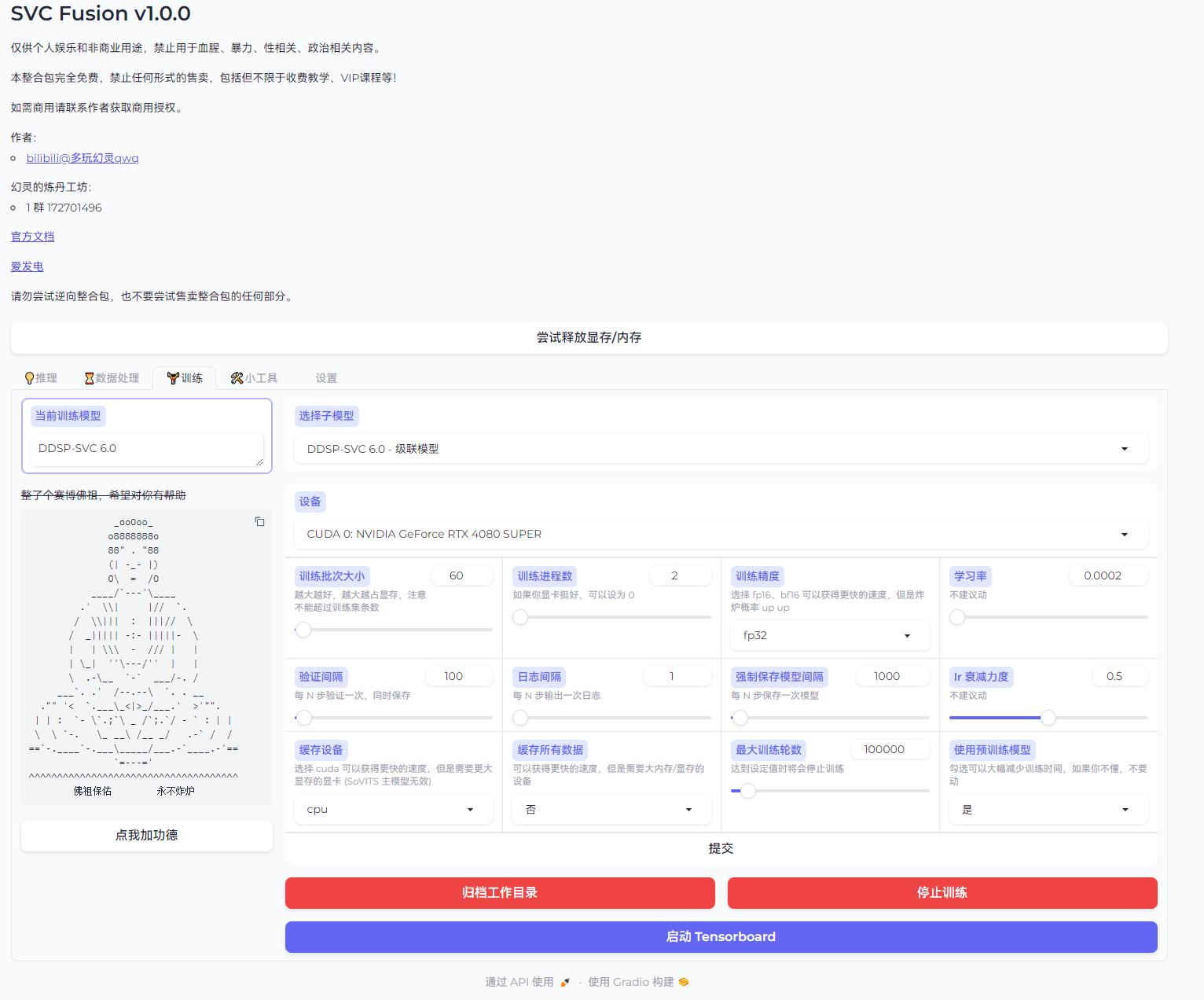
选择参数(一般为默认参数,默参也能用)
以下为训练参数详解:
| 参数名称 | 说明 |
|---|---|
| 训练批次大小 | batch_size(bs),越大越好,越大越占显存,注意不能超过训练集条数。根据显存酌情调整,一般默认的数值不会爆显存 |
| 训练进程数 | 如果你显卡较好,可以设为 0,会提升速度但不影响质量 |
| 训练精度 | 默认 fp32(单精度),选择 fp16(半精度)、bf16(混合精度) 可以获得更快的速度和更低的显存占用,但是炸炉概率 up up |
| 验证间隔 | 每 N 步验证一次,同时保存。默认 1000 |
| 日志间隔 | 每 N 步输出一次日志。默认 1,建议改为 100,否则报告较为频繁(不影响质量) |
| 强制保存模型间隔 | 每 N 步保存一次模型。默认 1000 |
| lr 衰减力度 | 高级玩法,不建议动 |
| 缓存设备 | 选择 cuda 可以获得更快的速度,但是需要更大显存的显卡 (SoVITS 主模型无效),选择 cpu 则载入内存,减小硬盘 io 压力 |
| 缓存所有数据 | 若内存和显存较小则建议关闭, |
| 最大训练轮数 | 默认 100000,不建议动,正常不需要跑这么久 |
| 使用预训练模型 | 是否调用底模。勾选可以大幅减少训练时间,如果不懂不要动 |
确定参数后点击“提交”开始训练

等待弹出训练 bat
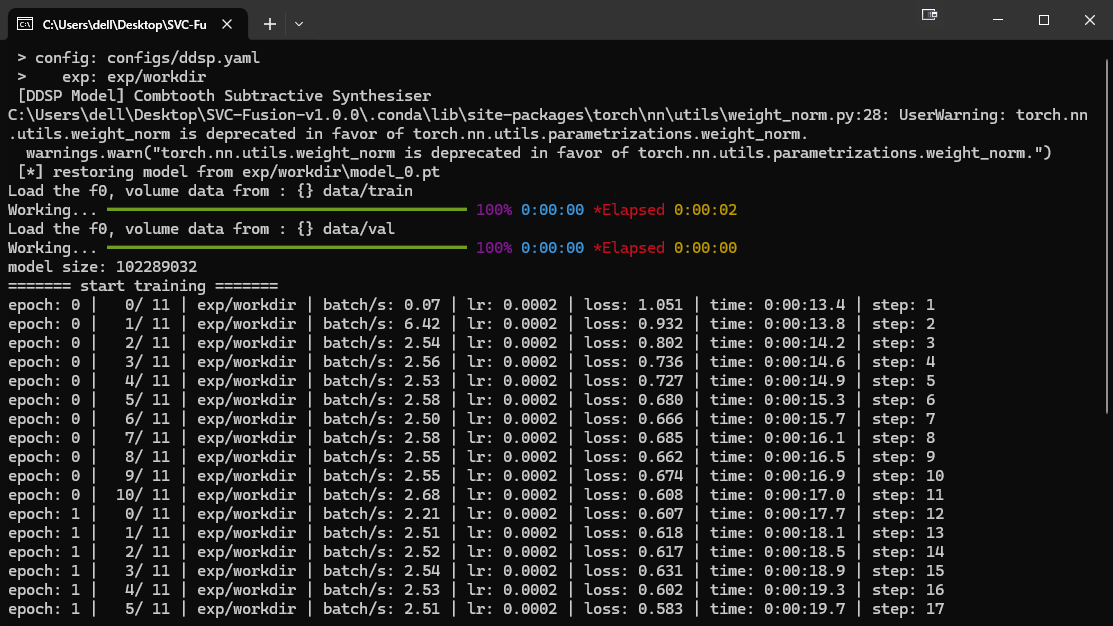
训练时长与数据集时长、质量、算法、预测器、bs、lr、GPU 相关,因此一般建议每 1000-2000 步(step)停下进行试听。
Tensorboard 可作为 loss 数值上的参考
训练日子参数和推荐训练步数会在文档 DLC 中发布
注意:不要迷信步数和 loss,无论哪个算法都不是炼的越久越好的!

结束、暂停训练请按停止训练(或直接关闭训练 bat)
5:推理
训练完成并归档后点击推理,来到推理界面
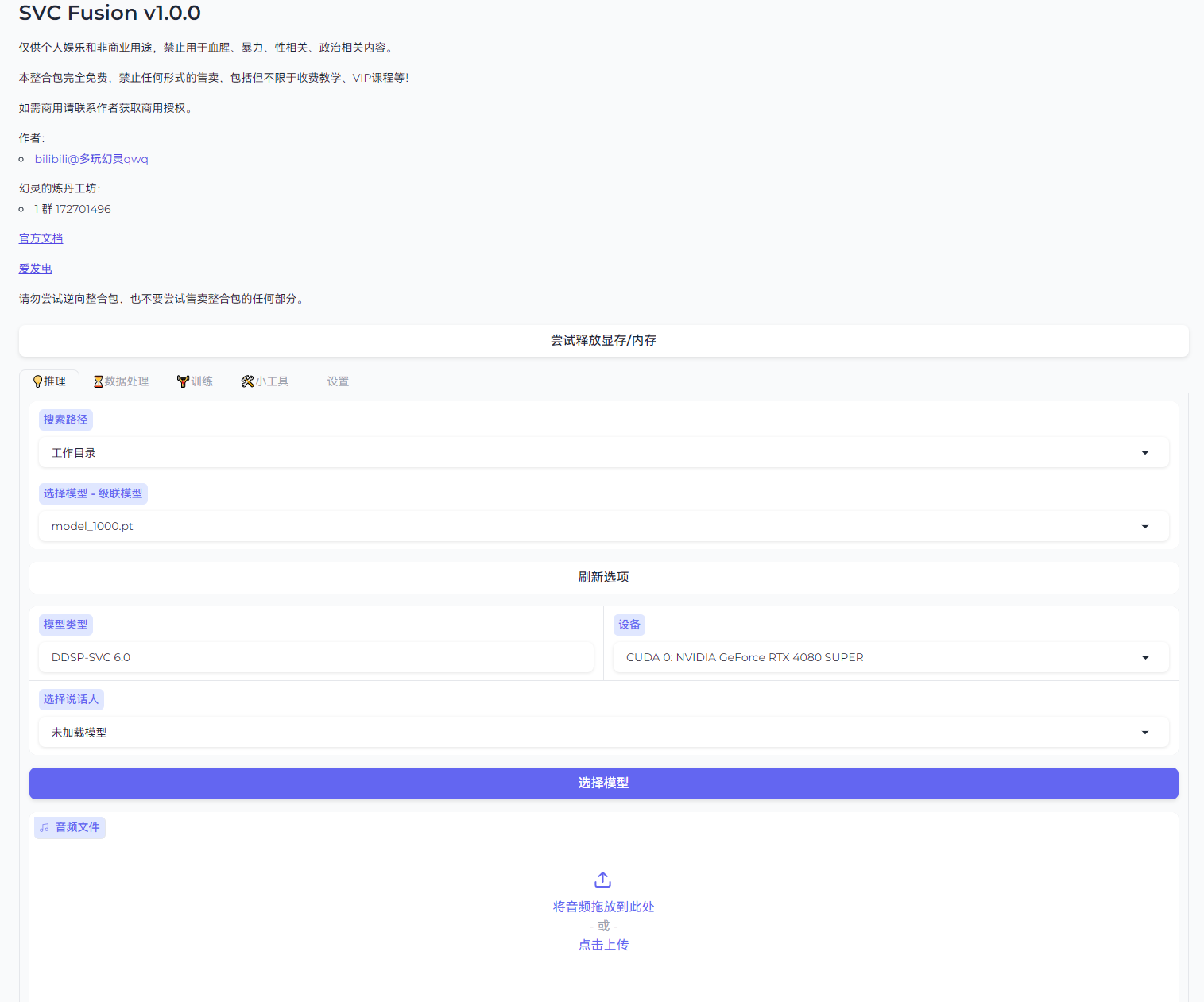
首先选择用于推理的模型


如果模型加载正常,则会显示相应的算法

接下来选择推理用的设备(优先使用 GPU)

点击选择模型进行加载
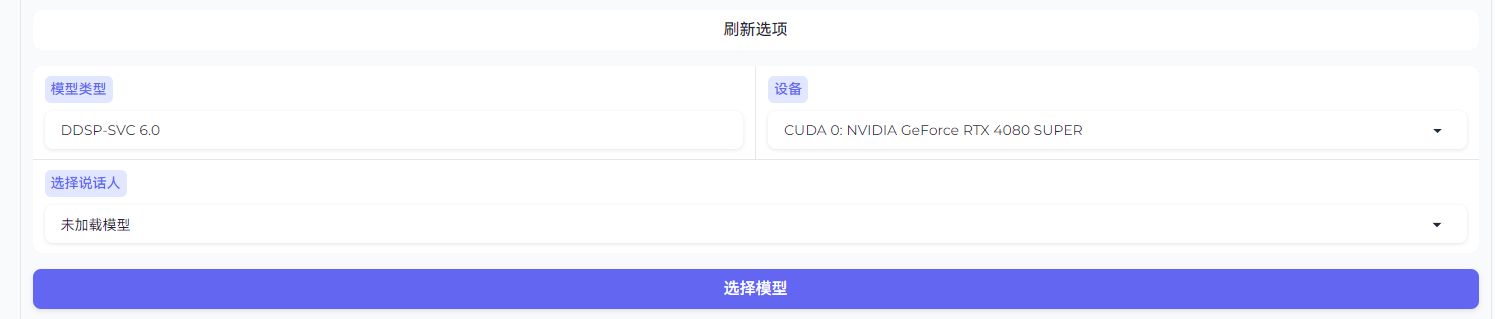
加载成功后会显示说话人

放入用于转换音色的音频文件(即推理源)
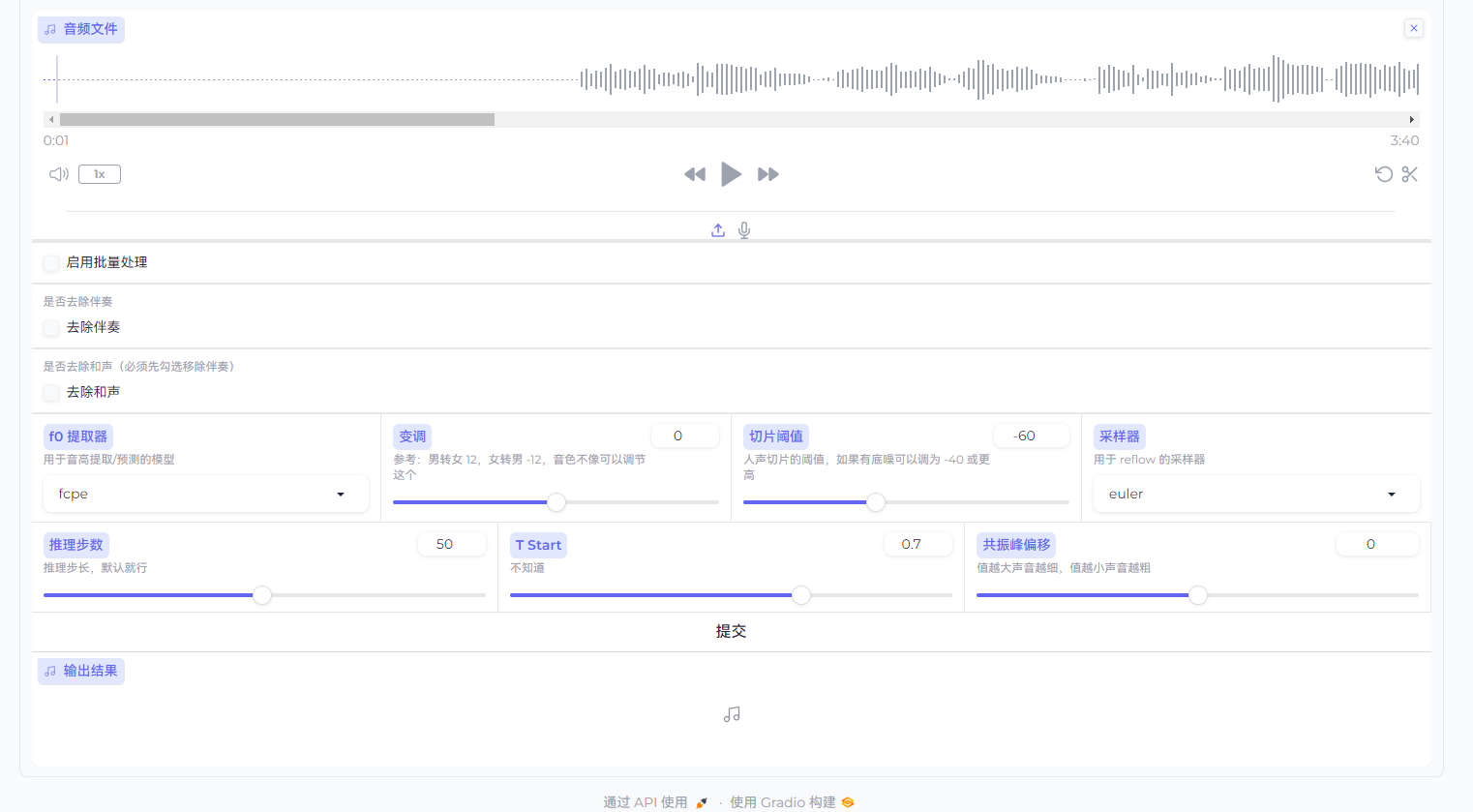
若推理源没有经过人声分离,则需要勾选去除伴奏(可视歌曲情况勾选去除和声)
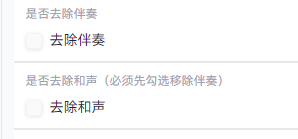
接下来选择推理参数

以下为推理参数详解:
| 参数名称 | 说明 |
|---|---|
| f0 提取器 | 用于音高提取/预测的模型,一般认为 remove 最均衡,fcpe 更自然(其余选项正在测试中,将在 DLC 中详细述) |
| 变调 | 每 12 为一个八度,参考:女模型转男原声 12,男模型转女原声 -12,因异性声调不同的音色泄露、失真可以调节这个 |
| 切片阈值 | 人声切片的阈值,如推理源有底噪可以调为 -40 或更高 |
| 采样器 | 用于 reflow 的采样器,一般默认就好(二者差异正在实验中) |
| 推理步数 | 推理步长,一般默认就行 |
| T Start | 控制 reflow 起点 |
| 共振峰偏移 | 值越大声音越细,值越小声音越粗,优先用变调,这个调了很难听 |

推理完成
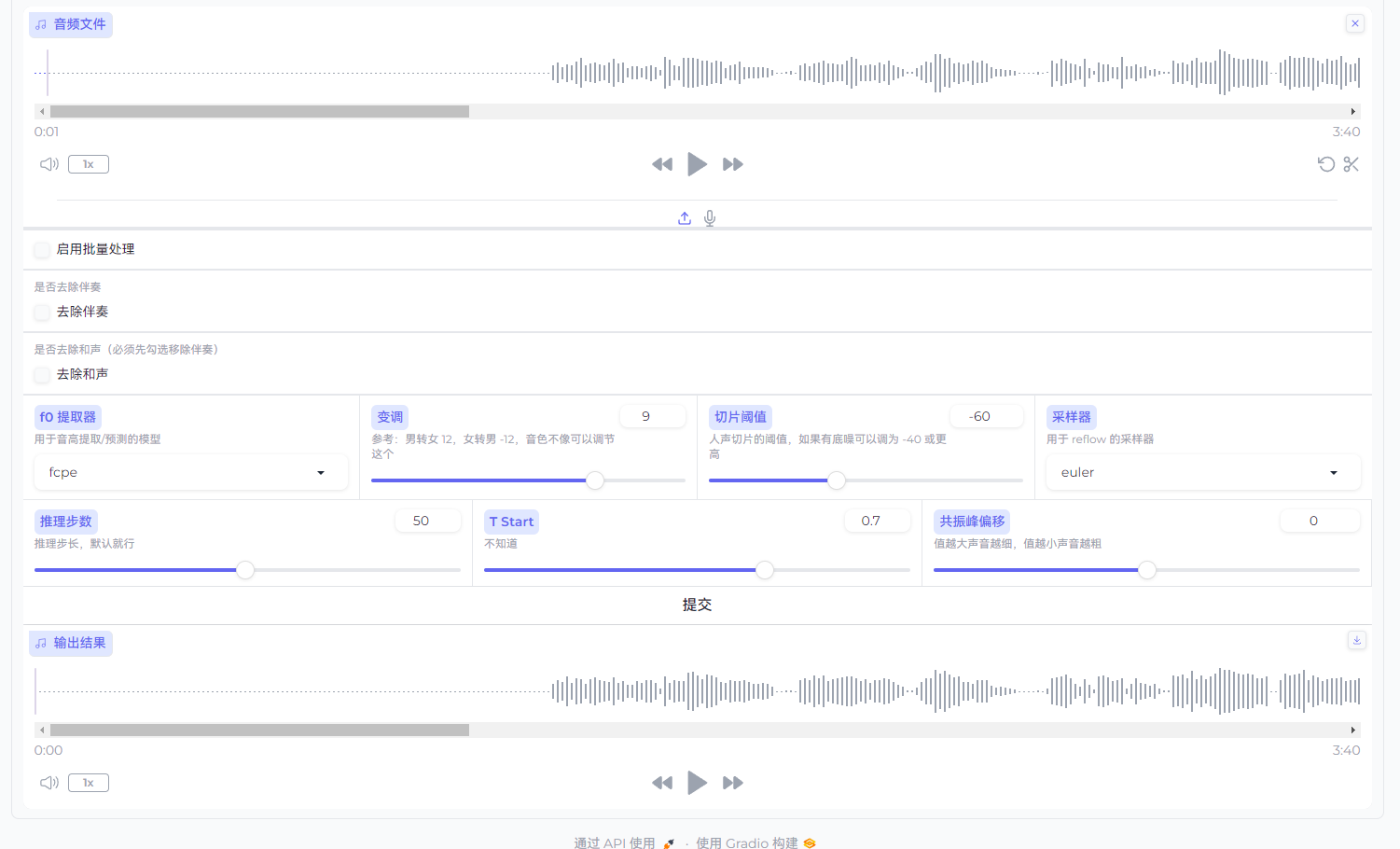
可以试听推理后的音频,并对参数进行微调
如果对音频比较满意,可以进行保存

保存完文件后,可以在其他软件内进行加伴奏、混音、和声等处理
常见错误及解决方法
下文搬运自 https://sf.dysjs.com/faq/
Authors:
The system cannot find the path specified.
- Tips :教你一个生活小技巧:压缩包要解压才能使用。
CUDA out of memory. Tried to allocate …
不要怀疑,你的显卡显存或虚拟内存不够用了。以下是 100% 解决问题的解决方法,照着做必能解决,请不要再在各种地方提问这个问题了
-
1.在报错中找到 XX GiB already allocated 之后,是否显示 0 bytes free,如果是 0 bytes free 那么看第 2, 3,4 步,如果显示 XX MiB free 或者 XX GiB free, 看第 5 步
-
2.如果是预处理的时候爆显存: 换用对显存占用友好的 f0 预测器(友好度从高到低:parselmouth >= harvest >= rmvpe ≈ fcpe >> crepe),建议首选 rmvpe 或 fcpe
-
3.如果是训练的时候爆显存:
- a. 检查数据集有没有过长的切片(20 秒以上)
- b. 调小批量大小
- c. 使用 cpu 进行训练
- d. 把你数据集写进内存,而不是缓存
- e. 或者开启数据随用随取
- f. 吃共享显存(绝对不推荐)
- g. 去 AutoDL 等云算力平台上面租一张大显存的显卡跑
-
4.如果是推理的时候爆显存:
- a. 推理源(干声)不干净(有残留的混响,伴奏,和声),导致自动切片切不开。提取干声最佳实践请参考歌曲人声分离
- b. 调大切片阈值(比如-40 调成-30,再大就不建议了,你也不想唱一半就被切一刀吧)
- c. 设置推理加速,同时会影响音频质量
- d. 使用 cpu 推理,速度会比较慢,但是不会爆显存
-
5.如果显示仍然有空余显存却还是爆显存了,那就是你的虚拟内存不够大,调整到至少 50G 以上。
Access is denied. Press any key to continue . . . \ ” ddsp.webui.exe ” is not recognized as an internal or external operable program or bantch file. Press any key to continue . . . \ ModuleNotFoundError: No module named ‘dist’ Press any key to continue . . .
- 关掉你那些该死的杀毒软件,包括 Windows Defender ,然后重新解压软件。
IMPORTANT: You are using gradio version 4.18.0, however version 4.29.0 is available, please upgrade.
- 这不是报错,不用管
内存错误
错误信息可能为:
- numpy.core._exceptions._ArrayMemnryEror:UInable to allocate 46.2 MiB for an array with shape(504576,6,2) anddata type f1oat64
- ImportError: DLL load failed while importing _multiprocessing: 页面文件太小,无法完成操作。
- MemoryError
解决方法:
- 1.开虚拟内存,如已开启请继续添加空间(操作方法请自行百度)
- 2.买个新内存
- 3.把数据扔进显存
- 4.开启随用随取
num_samples should be a positive integer value,but got num_samples=0
数据集过短,切不出验证,或者可能根本没数据集
fairseq.tasks.text_to_speech | Please install tensorboardX: pip install tensorboardX
- 没有问题,程序正在训练,请等待日志出现。
Error 请将你的数据集放到 dataset_raw/你的角色名字文件夹中
- 按照错误信息中的提示操作即可。
raise ValueError(‘ [x] nan ddsp_loss ‘) ValueError: [x] nan ddsp_loss
- 建议更换为
fp32进行训练,以解决此问题。
Connection errored out.
- 请勿关闭终端。关闭 WebUI 终端会导致无法连接。你把 WebUI 终端都关了当然连接不上了……
Error No such file or directory: data/train pitch aug_dict.npy
- 请重新进行数据预处理。
RuntimeError: Cannot load audio from file: ffprobe not found.Please install ffmpeg your system use non WAV dio file formats and make sure ffprobe is in your PATH
- 请确保已正确解压压缩包,并重新尝试。
AttributeError: ‘SoVITSModel’ object has no attribute ‘use_cluster’
- 请先加载模型
下载:【链接直达】
模型下载:
崩坏:【链接直达】











![表情[xiaojiujie]-创梦星际](https://www.scmgzs.top/wp-content/themes/zibll/img/smilies/xiaojiujie.gif)
![表情[aoman]-创梦星际](https://www.scmgzs.top/wp-content/themes/zibll/img/smilies/aoman.gif)

- 最新
- 最热
只看作者